Мы принимаем к оплате:
«Подарочный сертификат» от нашего Учебного Центра – это лучший подарок для тех, кто Вам дорог! Оплате обучение и подарите Вашим родным и близким обучение по любому из курсов!!!
«Сертификат на повторное обучение» дает возможность повторно пройти обучение в нашем Учебном Центре со скидкой 1000 рублей!
А также:
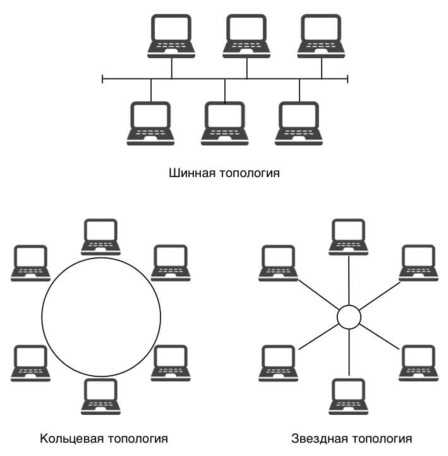
Как запараллелить два роутера
Настройка двух роутеров в одной сети. Соединяем два роутера по Wi-Fi и по кабелю
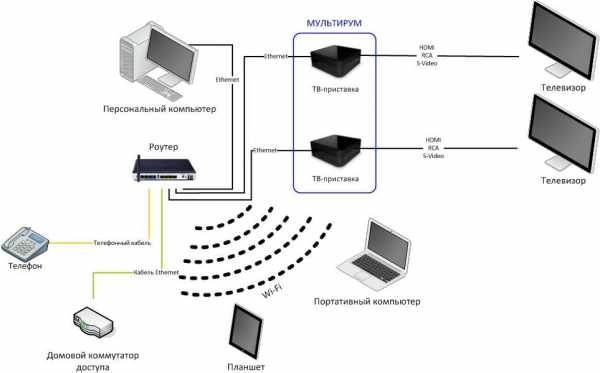
Рассмотрим в этой статье два варианта, которыми можно соединить роутеры между собой в одной сети. Первый вариант – соединение двух роутеров по Wi-Fi, а второй вариант – соединение роутеров по сетевому кабелю. В любом случае, роутеры будут работать в одной сети, и каждый будет раздавать интернет как по кабелю, так и по Wi-Fi.
Зачем вообще настраивать такую схему и зачем подключать один роутер к другому? Разные бывают ситуации. Чаще всего, это расширение зоны покрытия Wi-Fi сети, хотя, для таких задач я рекомендую использовать репитеры, или роутеры которые могут работать в режиме репитера. Здесь все очень просто. У нас уже установлен и настроен роутер, или модем, который раздает интернет. Мы к этому роутеру подключаем второй, по беспроводной сети, или с помощью сетевого кабеля. Установив второй маршрутизатор в другой комнате, или на другом этаже, он будет раздавать Wi-Fi дальше.
Или же таким способом можно подключить интернет от соседа. Платить за одно подключение, и делить его на два роутера. На самом деле, вариантов очень много. И если вы уже зашли на эту страницу, то скорее всего уже знаете для чего вам подключать один роутер ко второму. Поэтому, давайте перейдем ближе к делу.
Совет! Если вы хотите настроить такую схему исключительно для расширения уже существующей Wi-Fi сети, то лучше всего настраивать роутер в режиме репитера, если он поддерживает такую функцию. Устройства от Asus и Zyxel так умеют, вот инструкции:Два роутера в одной сети: варианты соединения
Есть два варианта:
- Соединить роутеры по Wi-Fi сети. В режиме WDS, или режим моста. Это одно и то же. В таком случае, можно установить их на относительно большом расстоянии. Ну и кабеля прокладывать не нужно. Но есть и минусы, соединение по Wi-Fi не очень стабильное, так же упадет скорость по беспроводной сети. Если у вас никак не получается использовать для соединения кабель, то вариант с беспроводным соединением вам подойдет. Ну и не каждый роутер поддерживает режим WDS (особенно из старых устройств).
- Второй вариант – соединение двух роутер с помощью сетевого кабеля в одной сети. Способ надежный, проверенный, но не всегда он подходит и-за того, что приходится прокладывать кабель, да и сам кабель, как правило, нужен длинный и его уже нужно либо покупать, либо делать самому. Можно использовать тот, который идет в комплекте с роутером, но он короткий.
Думаю, вы уже выбрали подходящий для себя способ соединения. Сейчас рассмотрим их более подробно.
Соединяем два роутера по Wi-Fi (в режиме WDS)
Рассмотрим мы на примере самых популярных производителей: Asus, Tp-Link, Zyxel, и D-link.
Значит, у вас должен быть главный роутер, который должен раздавать Wi-Fi сеть, к которой мы подключим второй. Он может быть любой. В том смысле, что не обязательно что бы это были например два роутера Tp-Link (хотя желательно).
Нужно ли менять настройки главного роутера? Да. В настройках главного роутера нужно задать статический канал беспроводной сети. В противном случае, могут наблюдаться проблемы в работе соединения. Как сменить канал на разных роутерах, я писал в этой инструкции. Установите например статический 6 канал. И запомните его, он нам еще пригодится.Все, больше никакие настройки главного устрйоства изменять не нужно.
Настройка WDS соединения на роутере Tp-Link
По настройке такой схемы на Tp-Link, у нас есть отдельная, подробная инструкция: Настройка роутера Tp-Link в режиме моста (WDS). Соединяем два роутера по Wi-Fi. Если у вас Tp-Link (TL-WR740ND, TL-WR841N, TL-WR941ND, TL-MR3220, TL-WR842ND и т. д.), то можете смело переходить по ссылке.
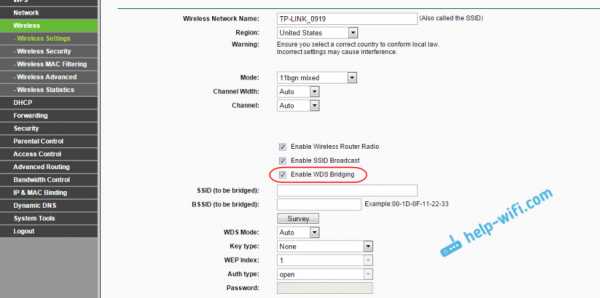
Там все очень просто: заходим в настройки, меняем IP адрес роутера, и настраиваем режим WDS. Не буду здесь все подробно описывать, так как по ссылке выше есть очень подробная инструкция. С Tp-Link разобрались, перейдем к моделям других производителей.
Настройка режима моста на роутере Asus
Сидел только что больше часа, разбирался что да как там с режимом моста на роутерах Asus, и могу сказать, что сделали они там все очень сложно и запутано. Насколько я понял, настроить WDS на роутере Asus можно только в том случае, если у вас главный роутер так же Asus. Там на обоих роутерах нужно прописывать MAC-адреса, и т. д. Возможно я ошибаюсь, поправьте меня (в комментариях). Проверял на Asus RT-N12, и RT-N18.
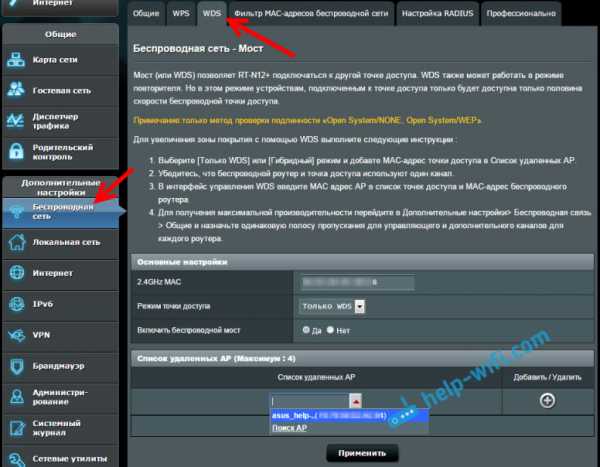
Вот у Tp-Link без всех этих заморочек все работает. Даю ссылку на инструкцию по настройке на официальном сайте Asus: https://www.asus.com/ua/support/faq/109839. А я обязательно разберусь с этими настройками, и подготовлю отдельную статью по настройке режима моста на маршрутизаторах Asus.
Или советую настроить его в режиме повторителя. Там все намного проще, и все работает. Проверено.
Подключение роутера D-Link к другому роутеру по Wi-Fi (режим клиента)
С D-Link я разобрался. Там этот режим называется "Режим клиента". Настроил, и все отлично работает. Главный роутер у меня Asus, а подключал к нему я D-link DIR-615 (с новой прошивкой 2.5.20).
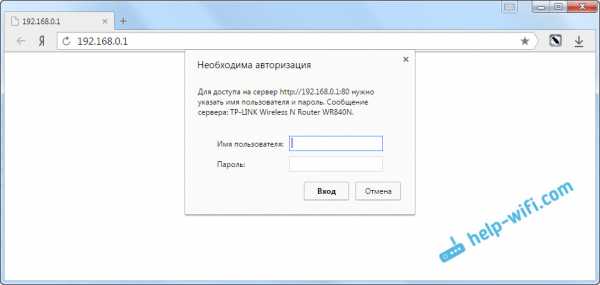
Для начала, подключаемся к нашему D-Link по кабелю, и заходим в настройки по адресу 192.168.0.1. Переходим сразу на вкладку Wi-Fi - Клиент. Ставим галочку возле Включить, в списке сетей выбираем свою сеть (главного роутера), в поле WPA-шифрование укажите пароль от вашей сети и нажмите на кнопку Применить. А если появится еще сообщение о смене канала, то нажмите Ok.
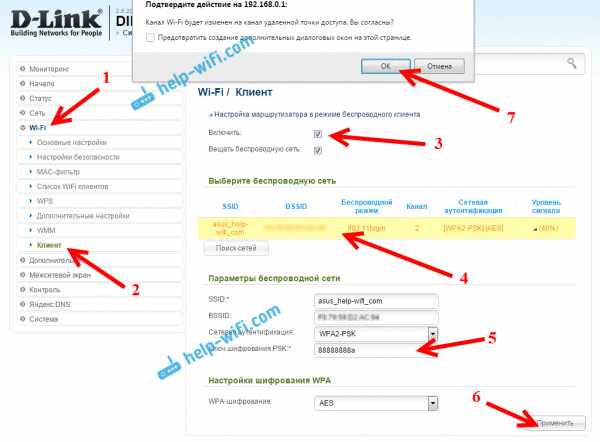
Дальше перейдите на вкладку Сеть - WAN. Выделите галочками все профили, которые там есть, и нажмите на кнопку Удалить.
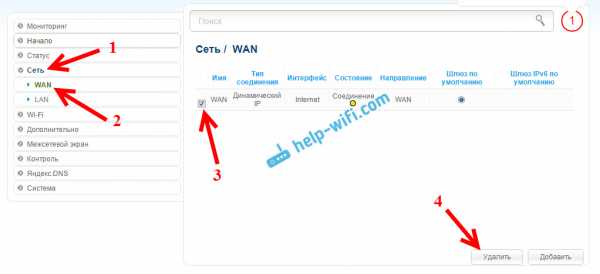
Затем, нажмите на кнопку Добавить, выберите в списке Динамический IP. В поле Интерфейс выберите пункт WiFiClient, и нажмите на кнопку Применить.
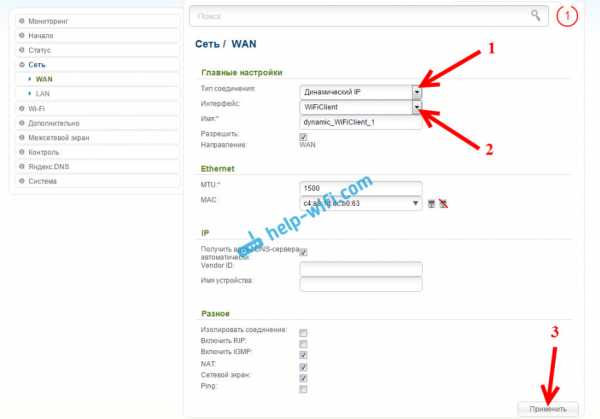
После этого нужно сохранить настройки нажав на пункт Система, и выбрав Сохранить. Затем снова наведите мышку на пункт Система и выберите Перезагрузить.
После этих настроек наш D-Link будет подключаться к главному роутеру по Wi-Fi сети, получать от него интернет, и раздавать его дальше по Wi-Fi, или по кабелю. Не забудьте поставить пароль на Wi-Fi сеть. Все работает, проверенно.
Соединение двух маршрутизаторов по Wi-Fi на Zyxel
На устройствах Zyxel Keenetic все отлично сделано. Там для использования роутера Zyxel Keenetic в режиме моста нужно настроить его на подключение к провайдеру по Wi-Fi. Этот режим еще называется WISP. В нашем случае, в качестве провайдера будет выступать главный роутер, который уже транслирует Wi-Fi сеть. Я уже писал подробную инструкцию с картинками по настройке этой схемы. Смотрите статью: режим клиента (беспроводной мост) на роутере Zyxel Keenetic.
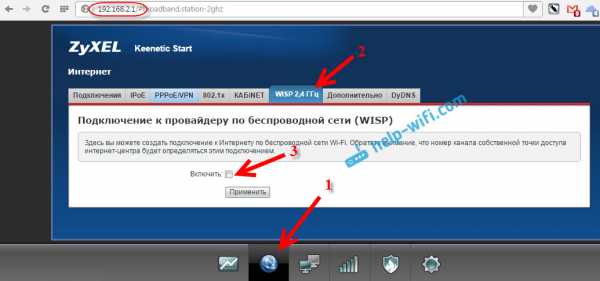
Ну или настройте свой Zyxel Keenetic в качестве репитера. Он с этой работой отлично справляется. Разница между этими режимами в том, что в первом случае (при настройке WISP) второй роутер будет раздавать интернет по своей Wi-Fi сети, то есть, их будет две. И вы сможете пользоваться всеми функциями роутера. А при настройке в режиме репитера, беспроводная сеть будет одна, просто усиливаться за счет второго устройства.
Как соединить два роутера по кабелю?
Давайте еще более подробно рассмотрим второй вариант – соединение по сетевому кабелю. Отлично подойдет в том случае, если нет проблем с прокладкой кабеля, или когда у вас модем (который например вам выдал провайдер) не умеет раздавать Wi-Fi. В таком случае, к нему можно просто подключить Wi-Fi роутер по этой схеме.
Важно! Так как у нас инструкция по настройке двух роутеров в одной сети, то схема подключения LAN-WAN описанная ниже не подходит. Все будет работать, но роутеры не будут находиться в одной сети, так как на втором роутере включен DHCP-сервер. Чтобы роутеры находились в одной сети, нужно на втором отключить DHCP-сервер и соединить их по схеме LAN-LAN. Подробнее в инструкции: как роутер сделать точкой доступа Wi-Fi.Нам понадобится простой сетевой кабель. Например тот, который был в комплекте с роутером. Если вам нужен более длинный кабель, то вы можете заказать его в каком-то компьютером магазине, там должны сделать кабель нужной вам длинны.
На главном роутере (модеме) настраивать ничего не нужно. Главное, что бы на нем был включен DHCP-сервер. Автоматическая раздача IP-адресов. Он скорее всего включен по умолчанию.
Я покажу на примере подключения роутера Tp-Link к D-Link (он у нас главный и черный). Значит берем кабель, и на главном роутере подключаем его в LAN разъем (в один из четырех, если их у вас 4). А на втором роутере подключаем кабель в WAN разъем. Смотрите скриншот ниже. Маршрутизаторы у меня соединены кабелем черного цвета. Кабель белого цвета, это интернет, который подключен к главному роутеру.

Получается, что Tp-Link будет получать интернет от D-Link, и раздавать его по беспроводной сети, или по кабелю.
Если после подключения, интернет со второго роутера не заработает, то первым делом сделайте на нем сброс настроек, а затем проверьте, что бы в настройках роутера который мы подключаем, было выставлено автоматическое получение IP адреса (Динамический IP). На Tp-Link, это делается так:
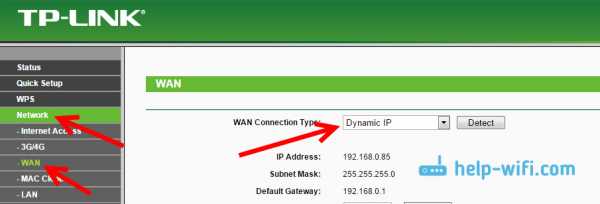
На других роутерах, эти настройки задаются в панели управления, на вкладке WAN, Интернет, и т. п.
Вот для примера еще схема подключения двух роутеров по кабелю: Tp-Link к Zyxel. В данном случае, у нас главный Tp-Link. К нему подключен интернет.

Точно по такой же схеме подключается роутер к ADSL модему.
Послесловие
Все что я написал в этой статье, я сам проверил, и все работает. Я старался подготовить максимально простую, и понятную инструкцию. Но, если у вас что-то не получилось, то вы можете описать свой случай в комментариях, постараюсь что-то посоветовать.
Ну и вы делитесь своим опытом. Если будет полезная информация, обязательно обновлю статью.
Параллелизм данных - Тим Деттмерс
В моем последнем сообщении в блоге я показал, на что следует обращать внимание при построении кластера GPU. Самое главное, вам нужно быстрое сетевое соединение между вашими серверами, и использование MPI в вашем программировании значительно упростит задачу, чем использование опций, доступных в самом CUDA.
В этом сообщении блога я объясняю, как использовать такой кластер для распараллеливания нейронных сетей различными способами, а также каковы преимущества и недостатки таких алгоритмов.Два разных алгоритма - это параллелизм данных и модели. В этой записи блога я сосредоточусь на параллелизме данных.
Так что это за два? Параллелизм данных - это когда вы используете одну и ту же модель для каждого потока, но вводите в нее разные части данных; параллелизм моделей - это когда вы используете одни и те же данные для каждого потока, но разделяете модель между потоками.
Для нейронных сетей это означает, что параллелизм данных использует одинаковые веса и разные мини-пакеты в каждом потоке; градиенты должны быть синхронизированы, т.е.е. усредненные, после каждого прохода через мини-серию.
Параллелизм моделей распределяет веса сети поровну между потоками, и все потоки работают в одном мини-пакете; здесь сгенерированный вывод после каждого слоя должен быть синхронизирован, то есть сложен, чтобы обеспечить ввод для следующего уровня.
У каждого метода есть свои преимущества и недостатки, которые меняются от архитектуры к архитектуре. Давайте сначала рассмотрим параллелизм данных и его узкие места, а в следующем посте я рассмотрю параллелизм моделей.
Серьезность сетевого узкого места параллелизма данных
Идея параллелизма данных проста. Если у вас, скажем, 4 графических процессора, вы разделите мини-пакет на части для каждого из них, скажем, вы разделите мини-пакет со 128 примерами на 32 примера для каждого графического процессора. Затем вы пропускаете соответствующую партию через сеть и получаете градиенты для каждого разделения мини-партии. Затем вы используете MPI для сбора всех градиентов и обновления параметров с помощью общего среднего значения.
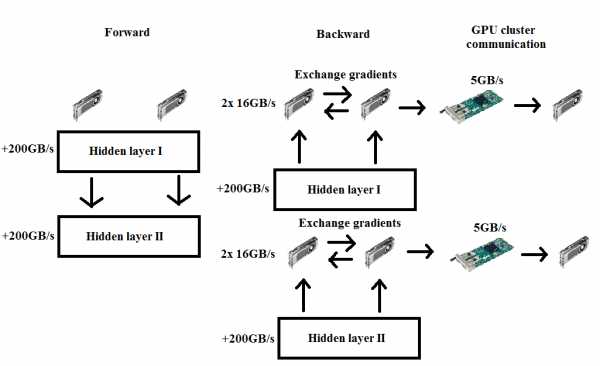 Диаграмма параллелизма данных.В прямом проходе нет связи, а во время обратного вы синхронизируете градиенты.
Диаграмма параллелизма данных.В прямом проходе нет связи, а во время обратного вы синхронизируете градиенты. Самая большая проблема с этим подходом заключается в том, что во время обратного прохода вы должны передать весь градиент всем другим графическим процессорам. Если у вас есть весовая матрица 1000 × 1000, вам необходимо передать 4000000 байт в каждую сеть. Если мы возьмем сетевую карту на 40 Гбит / с - а это уже довольно быстро - вам понадобится $ latex {\ frac {4000000} {40} \ frac {1} {40 \ times 1024 \ times 1024 \ times 102} \ frac {1} {8 \ times 1000} = 0.75 \ mbox {ms}} & bg = ffffff $ для передачи данных от одного узла к другому (однако есть некоторые дополнительные накладные расходы, которыми здесь пренебрегают). Если у вас шесть графических процессоров в двух узлах, вам необходимо передать данные пяти другим графическим процессорам, три из которых должны проходить через сетевую карту (3x 0,75 мс), а два могут использовать PCIe 3.0 для передачи данных на два других графических процессора. (примерно в три раза быстрее; 2x 0,25 мс). Однако проход PCIe не зависит от прохода сетевой карты, поэтому необходимое время определяется только временем сетевой карты, т.е.е. 2,25 мс. Однако только один графический процессор может передавать данные через сетевую карту в любой момент времени в любом узле, поэтому нам нужно умножить это время на три, то есть на 7,75 мс. Суть в том, что нам нужно примерно 0,2 мс для умножения матрицы через этот слой (100 × 1000 точек, 1000 × 1000) и примерно вдвое больше для обратного прохода. Мы можем передать градиент, пока работаем над следующим слоем, но, в конце концов, скорость сетевой карты немного ограничивает наши общие вычисления. Это становится более заметным, чем больше вы масштабируете свою систему: четырехузловой системе, работающей над той же проблемой, требуется около 20 узлов.25 мсек, чтобы передать градиенты другим графическим процессорам. Легко видеть, что параллелизм данных не зависит от размера кластера.
Чтобы противостоять этому узкому месту, необходимо уменьшить параметры градиента за счет максимального объединения, maxout единиц или простого использования свертки. Другой способ - увеличить соотношение вычислительного времени и сетевого времени другими способами, например с использованием ресурсоемких методов оптимизации, таких как RMSProp. Вам нужно одно и то же время, чтобы передавать градиенты друг другу, но больше времени тратится на вычисления, что увеличивает полезность быстрых графических процессоров.
Еще одна вещь, которую вы можете сделать при использовании методов оптимизации, требующих больших вычислительных ресурсов, - это скрыть задержку сети при вычислении градиентов. Это означает, что пока вы передаете первый градиент всем остальным узлам, вы уже можете асинхронно запустить большое вычисление RMSProp для следующего слоя. Этот метод может дать ускорение примерно на 0-20% в зависимости от сетевой архитектуры.
Но это не единственная проблема параллелизма данных. В архитектуре графического процессора скрыто узкое место с технической точки зрения, которое мне потребовалось довольно долго, чтобы понять.Чтобы понять, почему архитектура графического процессора является проблемой, нам сначала нужно взглянуть на использование и назначение мини-пакетов.
Расхождение: почему мы используем мини-партии?
Если мы начнем со случайно инициализированных параметров или даже если мы начнем с предварительно обученных параметров, нам не потребуется проходить через все данные, чтобы получить точное обновление градиента, которое направится в направлении локального минимума. Если мы возьмем MNIST в качестве примера, если у нас есть градиент, который включает 10 распространенных ошибок, которые сеть делает для каждого класса (размер мини-пакета около 128), тогда мы пойдем в направлении, которое значительно снижает ошибку уже как Градиент фиксирует грубые и типичные ошибки.Если мы выбираем больший размер пакета (скажем, 512), мы не только фиксируем общие ошибки, но и более тонкие. Однако не очень разумно настраивать систему, если вы знаете, что в ней все еще есть серьезные ошибки. Так что в целом мы мало выиграем от увеличения размера партии. Нам нужно больше вычислений, чтобы сделать примерно то же самое, и это главный аргумент, почему мы используем минимальный размер мини-партии. Однако, если мы выберем слишком маленький размер мини-партии, мы не улавливаем все общие ошибки, которые имеют отношение к набору данных, и, следовательно, наш градиент может не приближаться к локальному оптимуму, поэтому существует предел того, насколько мал можно делать мини-партии.
Как это связано с параллелизмом данных? Если нам нужен размер мини-пакета в 128 и использовать параллелизм данных, чтобы разделить его, скажем, между восемью графическими процессорами, тогда каждая сеть вычисляет градиенты для 16 выборок, которые затем усредняются с данными из других графических процессоров. И именно здесь возникает узкое место в оборудовании.
Плитки памяти: патчи быстрой памяти графического процессора для эффективных вычислений скалярного произведения
Для вычисления скалярных произведений на графическом процессоре вам необходимо скопировать небольшие патчи, называемые тайлами памяти, в общую память , я.е. очень быстрая, но очень маленькая память (ограничена несколькими килобайтами). Проблема в том, что стандартный cuBLAS использует тайлы памяти размером 64 × 128, а когда размер пакета меньше 64, вы тратите много драгоценной разделяемой памяти. Кроме того, если вы используете размер пакета, не равный кратному 32, вы одинаково тратите общую память (потоки запускаются только блоками из 32 потоков), поэтому следует использовать размер пакета, который кратен 32 или кратен 64, если это возможно. . Для параллелизма данных это означает, что вы теряете значительную скорость обработки, когда вы уменьшаете размер пакета в 64 для каждого графического процессора.Если у вас много графических процессоров, это может быть весьма ограничивающим фактором, и это еще одна причина, по которой подход параллелизма данных не масштабируется далеко за пределами определенной точки.
В целом это звучит довольно ужасно для параллелизма данных, но параллелизм данных имеет свои применения. Если вы знаете узкие места, вы можете использовать параллелизм данных как мощный инструмент для определенных приложений. Это продемонстрировал Алекс Кришевский в своей статье, где он использует параллелизм данных в сверточных слоях своей сети и, таким образом, достигает ускорения в 3 раза.74x при использовании четырех графических процессоров и 6,25x при использовании восьми графических процессоров. Его система включает в себя два процессора и 8 графических процессоров в одном узле, поэтому он может использовать полную скорость PCIe для двух наборов из четырех графических процессоров и относительно быстрое соединение PCIe между процессорами для распределения данных между всеми восемью графическими процессорами.
Помимо сверточных нейронных сетей, еще одним применением параллелизма данных может быть его использование в рекуррентных нейронных сетях, которые обычно имеют меньше параметров и высокопроизводительные вычисления градиента - и то, и другое является преимуществом для параллелизма данных.
В своем следующем сообщении в блоге я сосредоточусь на параллелизме моделей, который эффективен для больших сетей и хорошо масштабируется для больших кластеров.
.Параллелизм моделей- Тим Деттмерс
В моем последнем сообщении в блоге я объяснил, что такое параллелизм моделей и данных, и проанализировал, как эффективно использовать параллелизм данных в глубоком обучении. В этом сообщении я сосредоточусь на параллелизме моделей.
Напомним, параллелизм моделей - это когда вы разделяете модель между графическими процессорами и используете одни и те же данные для каждой модели; поэтому каждый графический процессор работает с частью модели, а не с частью данных. В глубоком обучении один из подходов состоит в том, чтобы сделать это путем разделения весов, например.грамм. матрица весов 1000 × 1000 будет разделена на матрицу 1000 × 250, если вы используете четыре графических процессора.
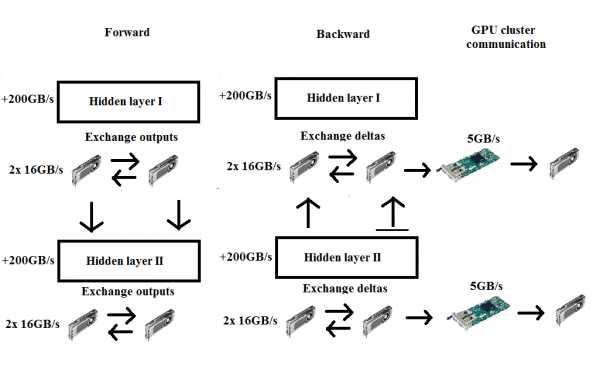 Схема параллелизма моделей. После каждого скалярного произведения необходима синхронизация обмена данными с весовой матрицей как для прямого, так и для обратного прохода.
Схема параллелизма моделей. После каждого скалярного произведения необходима синхронизация обмена данными с весовой матрицей как для прямого, так и для обратного прохода. Одно преимущество этого подхода очевидно сразу: если мы разделим веса между графическими процессорами, мы можем получить очень большие нейронные сети, веса которых не поместятся в памяти одного графического процессора. Частично я упоминал об этом в более раннем сообщении в блоге, где я также сказал, что такие большие нейронные сети в значительной степени не нужны.Однако для очень больших задач обучения без учителя - которые станут весьма важными в ближайшем будущем - такие большие сети потребуются для изучения мелкозернистых функций, которые могут обучать «интеллектуальному» поведению.
Как прямой и обратный проход работают с такими разделенными матрицами? Это наиболее очевидно, когда мы выполняем матричную алгебру шаг за шагом:
Мы начинаем смотреть на $ latex {\ bf {A}, \ bf {B} = \ bf {C}} & bg = ffffff $, который будет точкой матричное умножение для обычного случая прямого прохода.Размеры для использования параллелизма моделей с двумя графическими процессорами для размера пакета 128 и весовой матрицы 1000 × 500 будут следующими:
Стандарт: 128 × 1000 точек 1000 × 500 = 128 × 500
Первое измерение матрицы с разделением по весу: 128 × 500 точек 500 × 500 = 128 × 500 -> сложить матрицы
Разделить по весу второе измерение матрицы: 128 × 1000 точек 1000 × 250 = 128 × 250 -> суммировать матрицы
Чтобы вычислить ошибки в нижнем слое, нам потребуется чтобы передать текущую ошибку на следующий уровень или, более математически, мы вычисляем дельты, взяв скалярное произведение ошибки предыдущего слоя $ latex {i} & bg = ffffff $ и весов, которые связаны со следующим слоем $ латекс {j} & bg = ffffff $, i.T} = \ bf {delta_i}} & bg = ffffff $:
Стандарт: 128 × 500 точек 500 × 1000 = 128 × 1000
Первое измерение матрицы разделения по весу: 128 × 500 точек 500 × 500 = 128 × 500 - > Матрицы стека
Второе измерение матрицы разделения по весу: 128 × 250 точек 250 × 1000 = 128 × 1000 -> сложение матриц
Мы видим здесь, что нам необходимо синхронизировать (складывать или складывать веса) после каждого скалярного произведения, и думаю, что это медленно по сравнению с параллелизмом данных, когда мы синхронизируемся только один раз.Но можно быстро понять, что это не так для большинства случаев, если мы посчитаем: при параллелизме данных градиент 1000 × 500 необходимо передать один раз для слоя 1000 × 500 - это 500000 элементов; для параллелизма моделей нам просто нужно передать небольшую матрицу для каждого прямого и обратного прохода с общим количеством элементов 128000 или 160000 - это почти в 4 раза меньше данных! Таким образом, пропускная способность сетевой карты по-прежнему является основным узким местом для всего приложения, но в гораздо меньшей степени, чем в случае параллелизма данных.
Это, конечно, все относительно и зависит от сетевой архитектуры. Параллелизм данных будет довольно быстрым для небольших сетей и очень медленным для больших сетей, обратное верно для параллелизма моделей. Чем больше у нас параметров, тем выгоднее параллелизм моделей. Его истинная сила проявляется, если у вас есть нейронные сети, в которых веса не помещаются в память одного графического процессора. Здесь параллелизм моделей может достичь того, для чего потребуются тысячи процессоров.
Однако, если вы запускаете небольшие сети, где графические процессоры не загружены и имеют некоторую свободную емкость (не все ядра работают), то параллелизм моделей будет медленным.В отличие от параллелизма данных, здесь нет уловок, которые можно использовать, чтобы скрыть связь, необходимую для синхронизации, потому что у нас есть только частичная информация для всего пакета. Имея эту частичную информацию, мы не можем вычислить действия на следующем уровне и, следовательно, должны дождаться завершения синхронизации, чтобы двигаться вперед.
Как можно сочетать преимущества и недостатки, лучше всего показывает Алекс Крижевский, демонстрирующий эффективность использования параллелизма данных в сверточных слоях и параллелизма модели в плотных слоях сверточной нейронной сети.
.python - как использовать многопроцессорность для распараллеливания двух вызовов одной и той же функции с разными аргументами в цикле for?
Переполнение стека- Около
- Товары
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
Распараллеливание двух циклов for с помощью OpenMP в C ++ не дает лучшей производительности
Переполнение стека- Около
- Товары
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
- Вакансии Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимайте технических специалистов и создавайте свой бренд работодателя